object_recognition_capture: Data Capture¶
Contents
- Capturing data about an object to perform object recognition requires the following:
- knowing where the camera is with respect to a constant world frame
- knowing where the object is in the captured images/scans
- getting enough views to cover all aspects of an object
The third point depends on what is done with the captured data (e.g. computing a mesh a 3d model, templates ...) and is done by only requiring a given number of views.
The first point is currently done with a textured pattern (a dot pattern or a custom one) and is described in the Setup section.
The second point is currently done by segmenting out whatever is on top of the plane formed by the pattern.
capture uses the database infrastructure provided by object_recognition_core and object_recognition_capture to store the captured data.
3d Camera¶
Start your 3d sensor (Kinect, ASUS ...)
The standard openni drivers are used (not the ROS topics), so you just need to plug in your 3d camera.
Setup¶
Capture is view based, and requires a fiducial that is rigidly attached to the object being observed. This enables relatively accurate view point pose estimation, a consistent object coordinate frame, and simple object/background segmentation. The setup assumes that you have an RGB Depth device, such as the Kinect.
We have two methods of object captures, that have roughly equivalent quality results: a dot pattern and a generic pattern (which is useful if you cannot print the dot pattern)
Dot Pattern
One type of fiducial usable by object capture is the dot pattern. An svg is available here capture_board_big_5x3.svg and a pdf for printing here capture_board_big_5x3.svg.pdf.
{kind=link}
{kind=link}
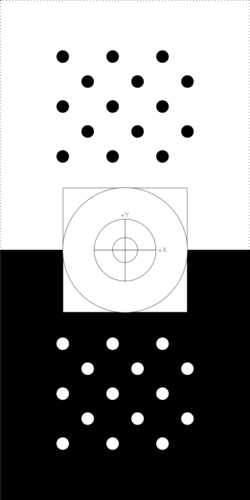
The dot pattern has two sets of fiducial markers: one black on white, the other inverted, so that two may be detected in the scene and allow for pose estimation in the presence of occlusion of one of the markers.
Get a full size printing of the above fiducial marker and mount it to flat surface, possibly on a lazy susan. http://en.wikipedia.org/wiki/Lazy_Susan
IMPORTANT: the physical size of the pattern actually does not matter as it is found in 2d and the proper scale is figured out using a Kinect-based plane finder.
ORB Template

If you are not inclined to print the dot pattern, you may use any highly textured planar surface. This involves capturing a canonical view of said surface to later establish an object coordinate system, and perform segmentation.
First capture an ORB template of your capture workspace. It should be taken from a planar frontal view, and the center of the image should be filled by the plane. Press ‘s’ to save an image. The result will be placed in the directory given, e.g. my_textured_plane. Press ‘q’ to quit the template capture program.
./apps/orb_template -o my_textured_plane
rosrun object_recognition_capture orb_template -o my_textured_plane
Try out tracking to see if you got a good template. Press ‘q’ to quit.
./apps/orb_track --track_directory my_textured_plane
rosrun object_recognition_capture orb_track --track_directory my_textured_plane
capture¶
capture is the entry point for using the our object capture system. The capture program will estimate a pose per view, along with a depth based mask. This will result in a ROS bag of data that has the following topics:
types: geometry_msgs/PoseStamped [d3812c3cbc69362b77dc0b19b345f8f5]
sensor_msgs/CameraInfo [c9a58c1b0b154e0e6da7578cb991d214]
sensor_msgs/Image [060021388200f6f0f447d0fcd9c64743]
topics: /camera/depth/camera_info 72 msgs : sensor_msgs/CameraInfo
/camera/depth/image 72 msgs : sensor_msgs/Image
/camera/mask 72 msgs : sensor_msgs/Image
/camera/pose 72 msgs : geometry_msgs/PoseStamped
/camera/rgb/camera_info 72 msgs : sensor_msgs/CameraInfo
/camera/rgb/image_color 72 msgs : sensor_msgs/Image
To use capture you should place your object in the center of the fiducial board, and keep it in the same location for the entirety of the capture session. Slowly turn the fiducial board, and the program should capture views that are evenly distributed in a view pose sphere.
Run the capture program in preview mode and make sure the pose of the pattern is displayed and the mask of the object non-empty (it should display the initial image by replacing anything but the object with black). The mask represents everything that is in a cylinder centered at the pose object and with dimensions specified through the command line. This is what clusters the object out and that is fed for training.
If you don’t have a pattern and use the dot pattern, ommit the -i option below:
./apps/capture -i my_textured_plane --seg_z_min 0.01 -o silk.bag --preview
rosrun object_recognition_capture capture -i my_textured_plane --seg_z_min 0.01 -o silk.bag --preview
You should see a popup image similar to the following:

A sample sequence of view captured using an opposing dot pattern fudicial marker.
When satisified by the preview mode, run it for real. The following will capture a bag of 60 views where each view is normally distributed on the view sphere. The mask and pose displays should only refresh when a novel view is captured. The program will finish when 36 (-n) views are captured. Press ‘q’ to quit early.
./apps/capture -i my_textured_plane --seg_z_min 0.01 -o silk.bag
rosrun object_recognition_capture capture -i my_textured_plane --seg_z_min 0.01 -o silk.bag
Remember to query the program for help if you are lost:
usage: capture [-h] [-o BAG_FILE] [-a RADIANS] [-n NVIEWS] [--preview]
[-i,--input INPUT] [-m,--matches] [--fps FPS] [--res RES]
[--seg_radius_crop SEG_RADIUS_CROP] [--seg_z_crop SEG_Z_CROP]
[--seg_z_min SEG_Z_MIN] [--niter ITERATIONS] [--shell] [--gui]
[--logfile LOGFILE] [--graphviz] [--dotfile DOTFILE] [--stats]
Captures data appropriate for training object recognition pipelines.
Assumes that there is a known fiducial in the scene, and captures views of the
object sparsely, depending on the angle_thresh setting.
optional arguments:
-h, --help show this help message and exit
-o BAG_FILE, --output BAG_FILE
A bagfile to write to.
-a RADIANS, --angle_thresh RADIANS
The delta angular threshold in pose.Frames will not be
recorded unless they are not closer to any other pose
by this amount. default(0.174532925199)
-n NVIEWS, --nviews NVIEWS
Number of desired views. default(36)
--preview Preview the pose estimator.
-i,--input INPUT The directory of the template to use. If empty, it
uses the opposite dot pattern
-m,--matches Visualize the matches.
camera:
--fps FPS The temporal resolution of the captured data
--res RES The image resolution of the captured data.
seg options:
--seg_radius_crop SEG_RADIUS_CROP
The amount to keep in the x direction (meters)
relative to the coordinate frame defined by the pose.
~ (default: 0.20000000298)
--seg_z_crop SEG_Z_CROP
The amount to keep in the z direction (meters)
relative to the coordinate frame defined by the pose.
~ (default: 0.5)
--seg_z_min SEG_Z_MIN
The amount to crop above the plane, in meters. ~
(default: 0.00749999983236
multiple capture sessions¶
If you decided to take multiple bags of an object, from different view points, please concatenate the bags before upload. However, if you moved the object on the board, then you should consider these bags as seperate “sessions” of the same object.
There is a convenience script for this called concat.py
Usage: concat.py OUTPUT INPUT1 [INPUT2 ...]
upload¶
Once you have captured a bag of views, you will want to upload the bag to the database. This upload will contain all of the views in the bag, plus some meta information about the object. It assumed that each bag has one object, and this object has a consistent coordinate frame throughout the bag.
use¶
A typical command line session will look like:
% apps/upload -a 'Ethan Rublee' -e 'erublee@willowgarage.com' -i silk.bag -n 'silk' -d 'A carton of Silk brand soy milk.' --commit milk, soy, kitchen, tod
Uploaded session with id: 4ad9f2d3db57bbd414e5e987773490a0
% rosrun object_recognition_capture upload -a 'Ethan Rublee' -e 'erublee@willowgarage.com' -i silk.bag -n 'silk' -d 'A carton of Silk brand soy milk.' --commit milk, soy, kitchen, tod
Uploaded session with id: 4ad9f2d3db57bbd414e5e987773490a0
If you leave off the --commit the script will run without actually committing anything to the database.
Now that the bag is uploaded, into the database, you can see it in the db by browsing to:
command line interface¶
usage: upload [-h] [-i BAG_FILE] [-n OBJECT_NAME] [-d DESCRIPTION]
[-a AUTHOR_NAME] [-e EMAIL_ADDRESS] [--visualize]
[--db_type DB_TYPE] [--db_root DB_ROOT_URL]
[--db_collection DB_COLLECTION] [--commit] [--niter ITERATIONS]
[--shell] [--gui] [--logfile LOGFILE] [--graphviz]
[--dotfile DOTFILE] [--stats]
TAGS [TAGS ...]
Uploads a bag, with an object description to the db.
positional arguments:
TAGS Tags to add to object description.
optional arguments:
-h, --help show this help message and exit
-i BAG_FILE, --input BAG_FILE
A bag file to upload.
-n OBJECT_NAME, --object_name OBJECT_NAME
-d DESCRIPTION, --description DESCRIPTION
-a AUTHOR_NAME, --author AUTHOR_NAME
-e EMAIL_ADDRESS, --email EMAIL_ADDRESS
--visualize Turn on visualization
Database Parameters:
--db_type DB_TYPE The type of database used: one of [CouchDB]. Default:
CouchDB
--db_root DB_ROOT_URL
The database root URL to connect to. Default:
http://localhost:5984
--db_collection DB_COLLECTION
The database root URL to connect to. Default:
object_recognition
--commit Commit the data to the database
Willow users¶
Some pre-acquired bags exist internally for now, just rsync them:
rsync -vPa /wg/wgss0_shelf1/object_recognition_capture ./